

Toronto Traffic Collision – Kaggle
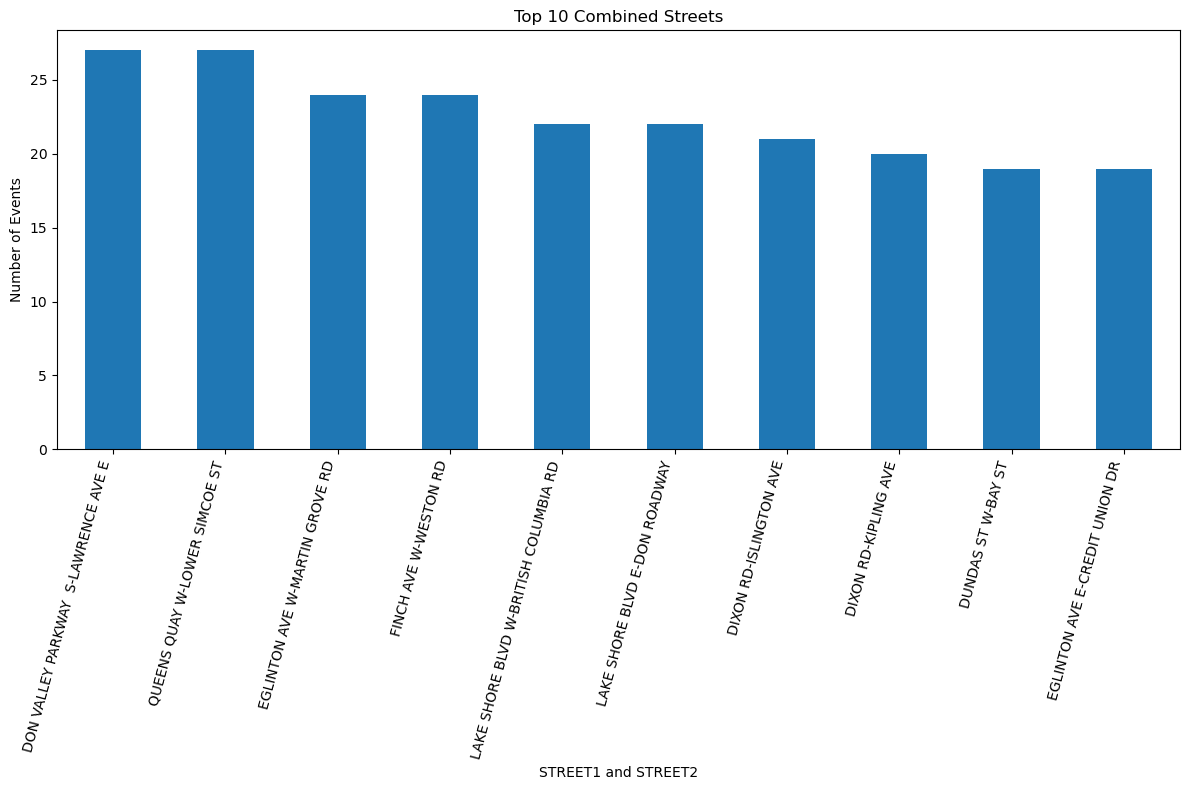
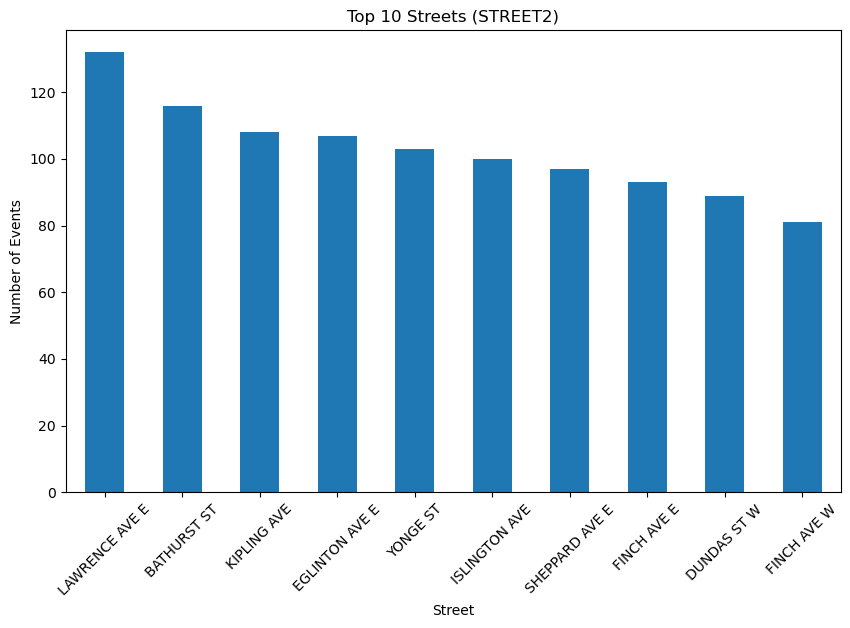
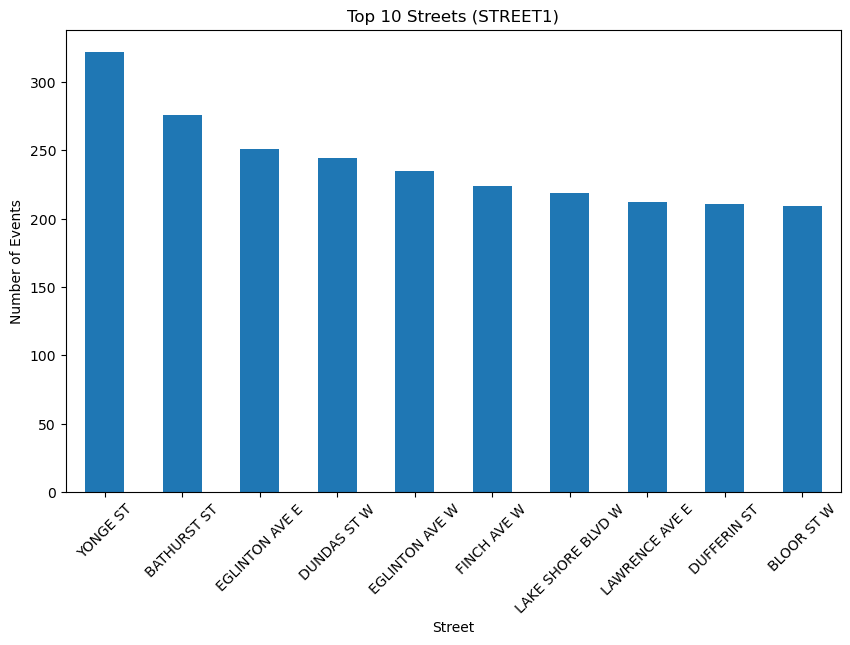
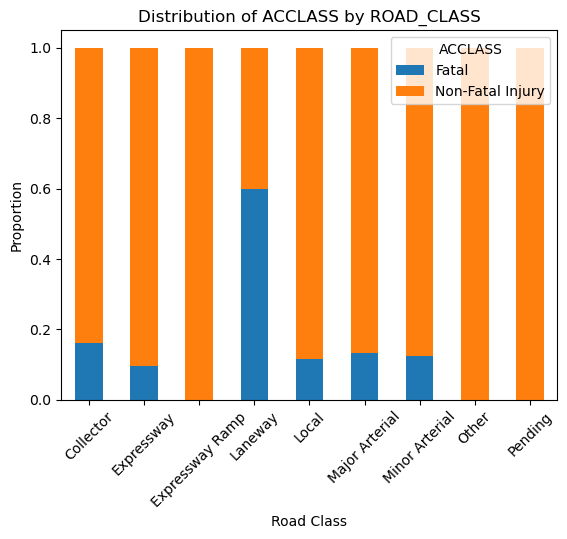
Description
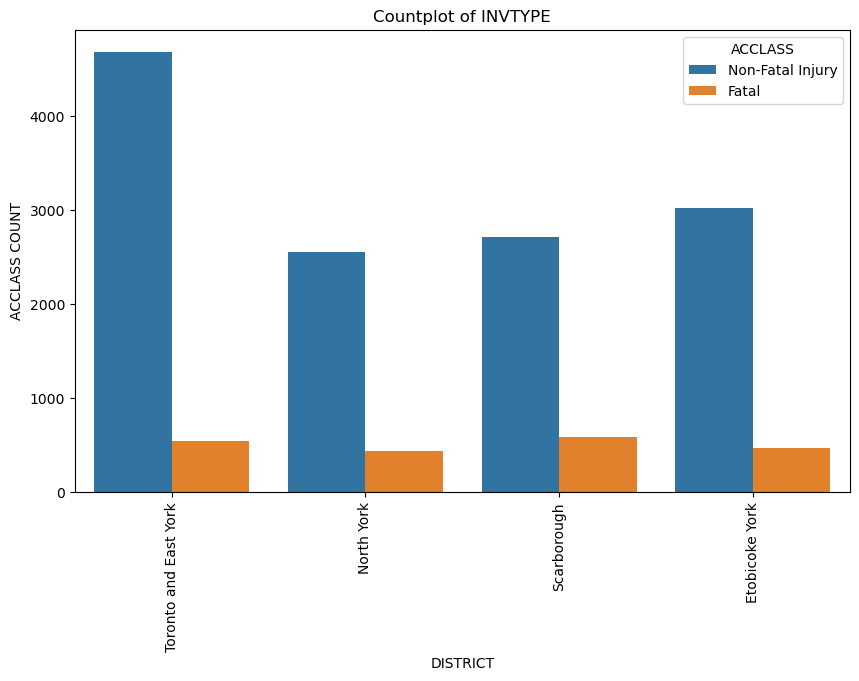
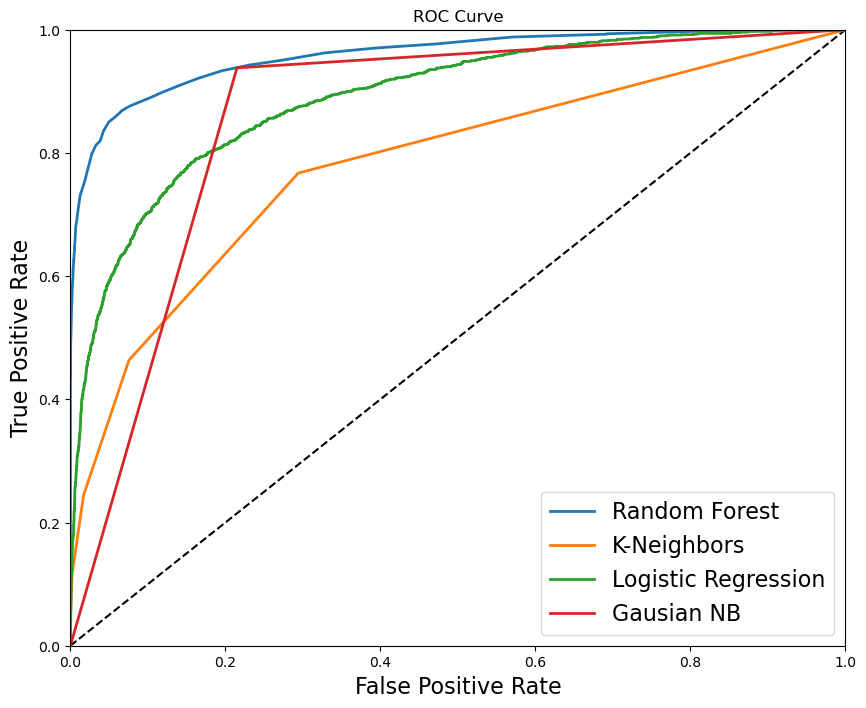
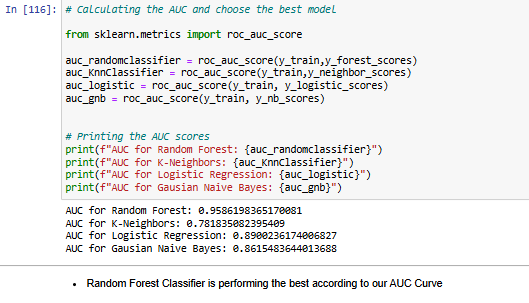
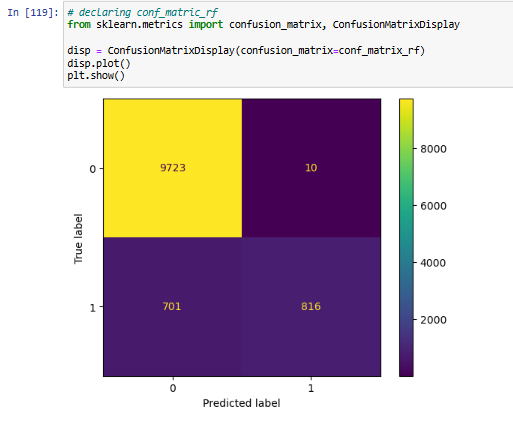
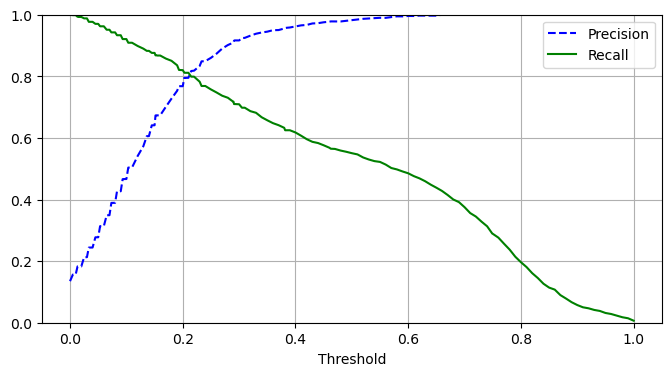
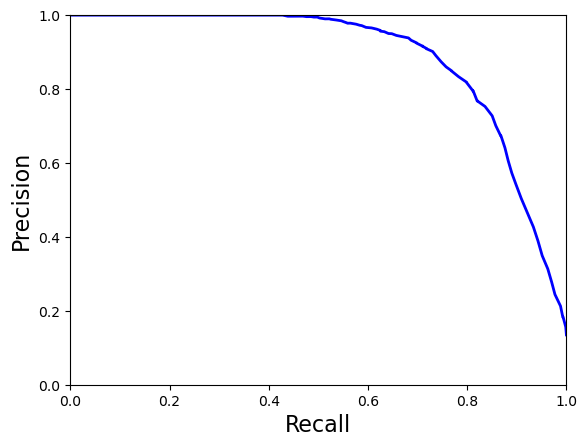
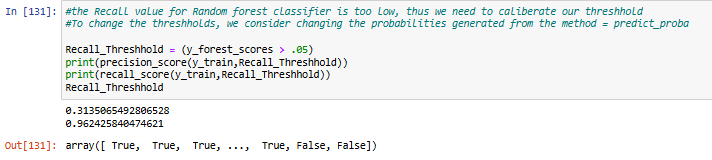
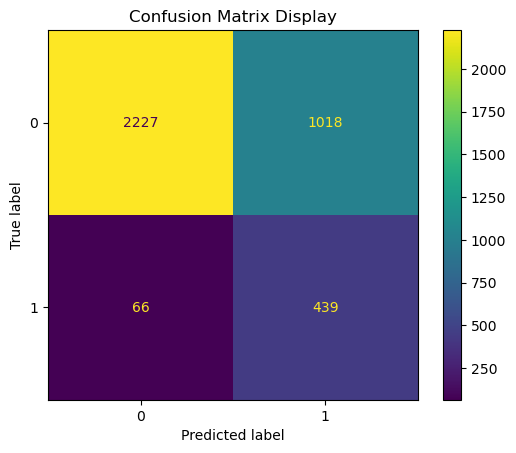
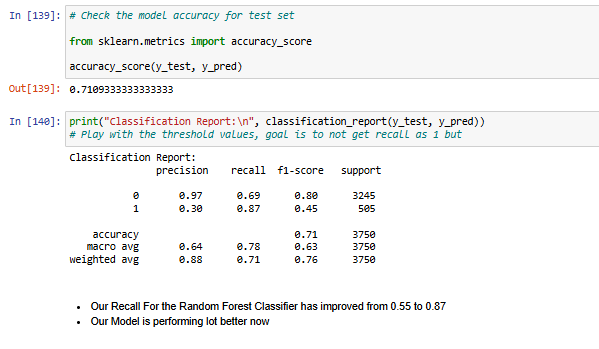
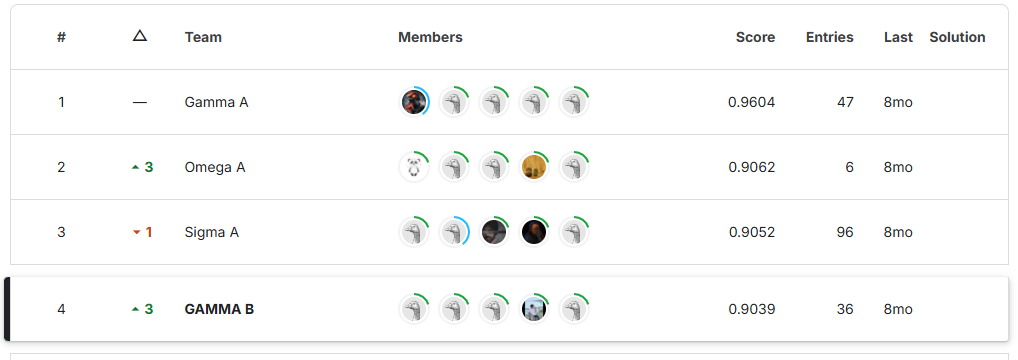
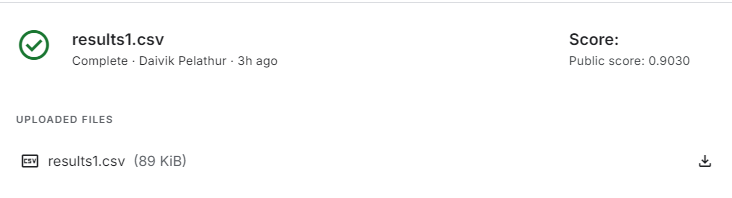
This project focuses on predicting the severity of traffic collisions using machine learning techniques. Based on a dataset of police-reported collisions from 2006-2022, we built and optimized models to classify accidents as fatal or non-fatal. By leveraging Random Forest Classifier, feature engineering, and Grid Search CV, we achieved 90.39% accuracy and secured 4th place in the Kaggle competition.